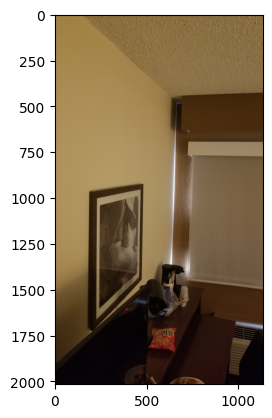
Original iPad
Original iPad
|
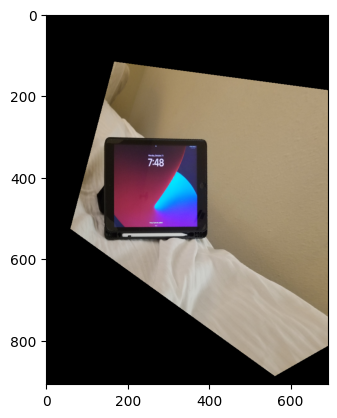 Rectified iPad
Rectified iPad
|
Blending Images
To blend images, I used some of my code from Project 2 as reference, particularly the part regarding blending with Laplacian pyramids. The key difference in this section is computing the mask that allows us to blend both images. Previously, it was a half white, half black mask because we wanted half of an apple and half of an orange. This time, we need to compute a distance map that determines how much of an impact the images should have in the blend for different parts of the total image. We also need to create a canvas that can hold both images, so we have a true merging of images, instead of one just overlapping the other.
 Result 1
Result 1
|
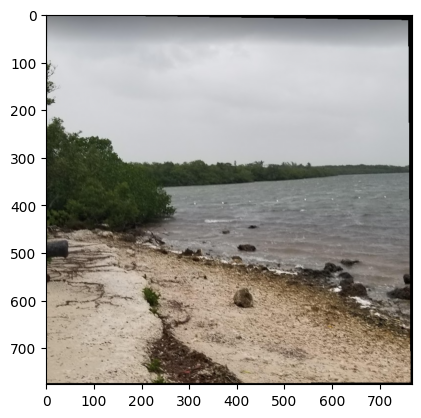 Result 2
Result 2
|
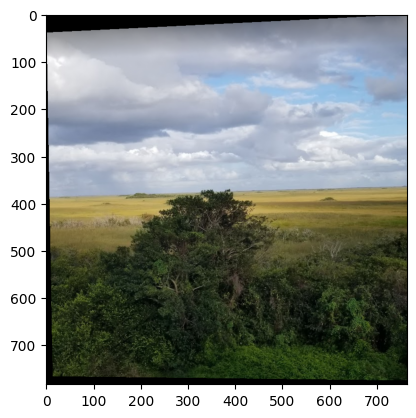 Result 3
Result 3
|
Project 4B: Feature Matching & Autostitching
Harris Corner Detection
We are given a function for this section that is able to detect Harris response values within an image, primarily using the corner_harris function from skimage.feature. Harris corners near the edge are discarded. Then, we essentially find the maxima across these values to identify the corner points. Importantly, we must input a grayscale image.
 Naiive Harris Corner Detection
Naiive Harris Corner Detection
|
Adaptive Non-Maximal Suppression
To implement Adaptive Non-Maximal Suppression, we want to select a specific set of strong corners by applying a robust condition to filter and find those points. We find other corners within the image with stronger Harris value and keep track of the smallest distances to these stronger corners. Then, we can get however many of the strongest corners we’d like, leading to a more evenly distributed set of points as shown below.
 ANMS Result
ANMS Result
|
Feature Descriptor Extraction + Matching
Here, for every corner we found in Adaptive Non-Maximal Suppression, we see if a 40x40 window around the points fits within the image. If it does, downsample it and look at every 8x8 patch. Then, we normalize each of these patches and return a list of all these descriptors. We run this algorithm on both images to get two descriptor sets. Then, for feature descriptor matching, we look at the first image’s descriptor set and find the indices of the two nearest neighbors in the other image’s descriptor set. Next, we apply Lowe’s ratio test, which finds matches where the distance to the closest neighbor is significantly smaller. For all places where this condition is satisfied, we add its pair of indices.
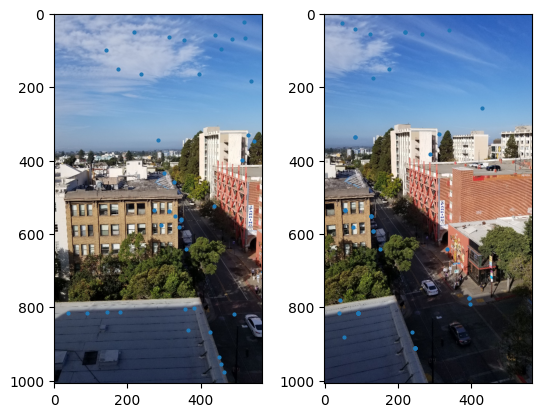 Matching Points between both images
Matching Points between both images
|
RANSAC
To implement 4-point RANSAC, we use steps outlined in lecture. In summary, we select four feature points at random, compute the homography, computer inliers that meet a specific distance condition, keep the largest set of inliers, and finally re-compute the least-squares H estimate on all the inliers. For each iteration, select 4 random correspondence points from the previous section and compute its homography. We use that H value to project the first image’s points onto the second image’s points. We calculate the distances between the projected and actual points for the second image and see which values are beneath the threshold. If the inlier count at this point of the iteration is more than we found previously, we update that counter and recalculate the resulting homography, which ultimately gets returned after all the iterations.
|
Result 1
|
Result 2
|
Result 3
|
The coolest thing in part 4B was implementing ANMS, which eliminated a lot of points and they were scattered pretty evenly across. This was a huge step in our correspondence point detection process.